簡介
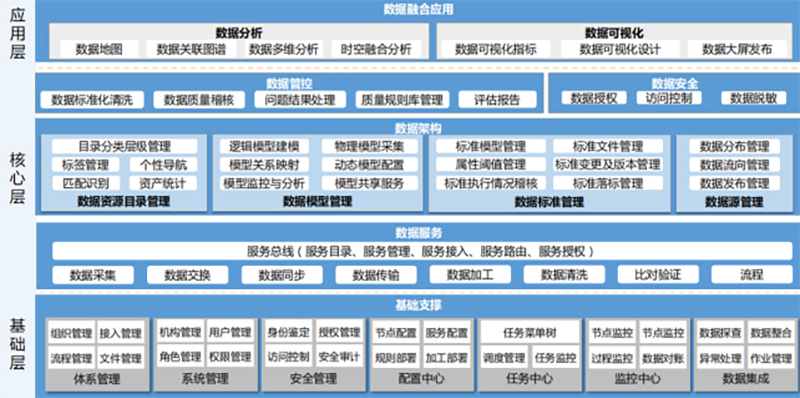
平台特色
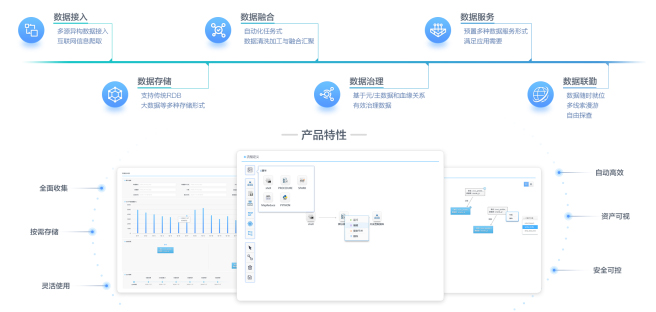
産品特色
豐富的數據接入手段
支持業務系統數據、互聯網數據、物(wù)聯網數據、空間地理數據、非結構化數據采集(視頻(pín)、音頻(pín)、圖像、文件…)、日志(zhì)類數據等多種數據接入場景。提供批流一(yī)體(tǐ)的數據遷移/同步、數據交換平台、ETL、網絡爬取、區塊鏈等滿足不同場景需要的接入手段。
面向使用的存儲劃分(fēn)
數據存儲依據加工(gōng)流程,劃分(fēn)爲ODS、MDS、ADS三層,對應于原始細節數據、中(zhōng)間加工(gōng)數據、數據倉庫以及最終面向業務領域的主題數據,各層均可按需組織數據,采用物(wù)理或邏輯隔離(lí),通過數據遷移工(gōng)具自動完成各存儲之間的數據同步。
強大(dà)的數據處理編排調度能力
支持數據處理流程的任務編排與調度,通過DAG圖的方式編排、配置數據加工(gōng)過程,從而支撐複雜(zá)的數據作業場景。支持數據處理流程的運行調度與監控,提供多種任務觸發機制,支持以甘特圖、流程圖的形式展示任務運行狀況。
支持連接多種主流的數據源,包括:
關系型數據庫,如MySQL、Oracle、SQL Server、PostgreSQL等
NoSQL數據庫,如MongoDB、Spark SQL、Druid、ClickHouse等
高效數據處理
支持配置規則、模式匹配、算法、ETL工(gōng)具等多種方式進行數據清洗、加工(gōng)計算、數據脫敏工(gōng)作,可高效快速的完成各類數據處理任務。
全面數據治理
支持元數據、主數據管理,提供數倉建模工(gōng)具,并通過表級、字段級質量監控與分(fēn)析以及智能化的數據血緣關系圖譜,幫助用戶全面進行數據治理工(gōng)作。
可視數據資(zī)産管理
以數據地圖、資(zī)源目錄、資(zī)源視圖等形式從業務、數據、存儲等多角度可視化的展示數據資(zī)産,并通過價值分(fēn)析與生(shēng)命周期統計幫助用戶洞察數據資(zī)産的使用情況。
批流一(yī)體(tǐ)大(dà)數據同步遷移
雙引擎數據遷移更高效,兩個引擎可以自由切換,确保不同量級數據量下(xià)的高效數據遷移。支持并發遷移,支持實時流數據遷移。
數據處理的全過程跟蹤分(fēn)析
完整記錄數據的全生(shēng)命周期,覆蓋數據接入、數據加工(gōng)處理、數據發布、數據銷毀的全過程。
智能數據血緣關系分(fēn)析
支持數據處理過程的自動解析,可自動跟蹤數據生(shēng)命周期全過程,根據數據處理過程中(zhōng)的SQL操作,自動解析并生(shēng)成完整的數據血緣關系。
方便快捷的裝配數據服務
基于元數據描述配置的數據查詢服務,屏蔽底層物(wù)理存儲結構,快速實現數據使用需求。提供不同數據存儲的适配,用戶無需關心不同存儲的數據查詢語句,降低數據使用難度。
數據展示:大(dà)屏可視化工(gōng)具
通過圖形化的界面輕松搭建專業水準的可視化應用,能夠把不同類型的數據以直觀多樣的方式呈現出來,滿足成果展示、業務監控、風險預警、地理信息分(fēn)析等多種業務的展示需求。
